-
The Statelessness of HTTP
The Statelessness of HTTP
- HTTP is a stateless protocol. This means that
- an HTTP session consists of a single request-response pair
- if a request-response exchange takes place and then another request comes in from the same client, HTTP does not know that it is from the same client and has no means of seeing that the new request is related to the previous one
- a web application, communicating through HTTP, cannot use that protocol as the means of maintaining state
- Why was HTTP made stateless?
- Stateful communication is more complex to implement, requires state recovery in the case of errors and commandeers more resources that stateless communication.
- In a set-up with inherently 'unreliable' clients, who may send a request, receive a response and quickly move on to something else, using a stateful protocol would simply be 'overkill'.
- Most of the communication on the WWW is casual in this sense and was even more so in the past, when the WWW was first created, hence the statelessness of HTTP.
- HTTP is a stateless protocol. This means that
-
The Application-Level Session
The Application-Level Session
- For web applications, which communicate by HTTP, the statelessness of HTTP poses a problem, as a lot of their functions need to remember the state of interaction with a client, for example:
- that a user is logged in
- that the user has performed some action, e.g. adding an item to an on-line shopping cart
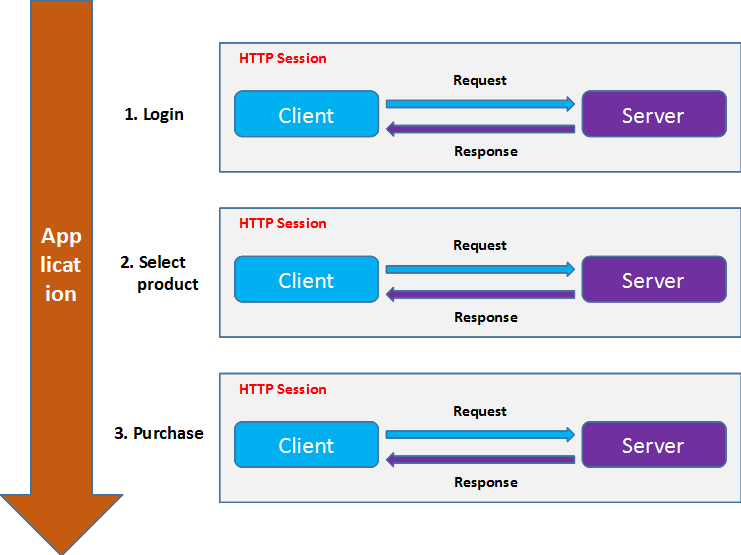
Figure: Session scope in the context of an application (picture by E. Lee) - How is the problem solved?
- The problem is solved by applications maintaining state information themselves.
- As a result of applications maintaining state information, communication at the level of the application becomes stateful.
- Effectively, application-level sessions are etablished.
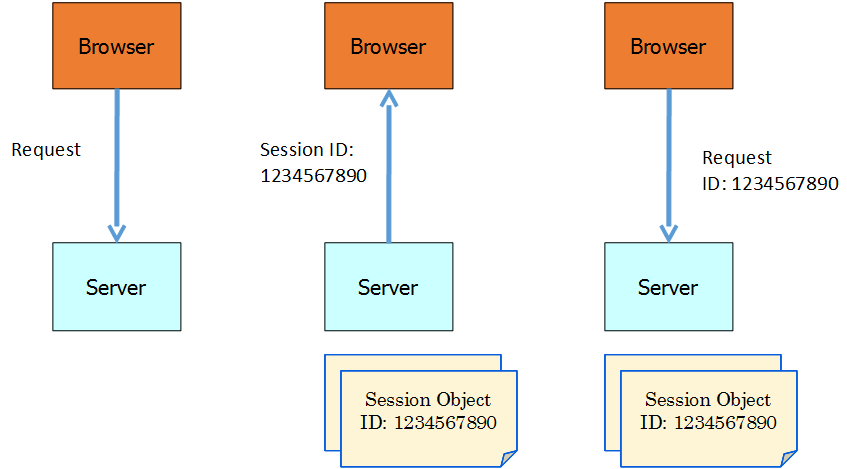
Figure: The flow of messages in a session (picture by E. Lee) - Three different mechanisms are used by aplications to maintain state information:
- cookies
- URL re-writing
- hidden form fields
- Implementation
- the developer does not parse and write HTTP messages directly
- APIs are provided by scripting languages and frameworks for session management
- For web applications, which communicate by HTTP, the statelessness of HTTP poses a problem, as a lot of their functions need to remember the state of interaction with a client, for example:
-
Cookies
Cookies
A cookie
- is a piece of information
- originates with the server
- is first sent in a cookie header field of an HTTP response message
- is sent back to the server in a cookie header field of new HTTP requests the same client makes to the same server
- having been received by the server allows the client to be identified as the sender of a previous request
- can be used as a session-identifying token
- or can be used simply as information about the client for the purpose of response customisation
- can be of two different types with regard to lifespan:
- session cookie - not written to the file system (e.g. database) on the client side and are destroyed when the browser is closed
- persistent cookie - saved onto disk by the browser
- may have an expiry date specified with the Expires attribute (this is deprecated but still in use)
- may have a maximal age (in seconds) specified with the Max-age attribute
- can have its scope within the server's domain specified:
- by default, the cookie is sent only to the exact domain and path of the resource that was requested
- if a Domain attribute is specified for the cookie, then the cookie is sent to the specified domain and all subdomains
- if a Path attribute is specified for the cookie, then the cookie is sent only to paths containing the specified path
- by default, can be accessed by HTTP or Javascript in the browser but if a cookie has the HttpOnly attribute then it may not be accessed by Javascript (this helps avoid cross-site scripting, XSS)
- by default, can be sent both by HTTP and HTTPS but if a cookie has the Secure attribute then it may be sent only using HTTPS
- is sometimes used specially for the purpose of tracking and analysis of user activities on the web and in that case is called a tracking cookie (tracking cookies are often used by advertisers with advertisements embedded in pages of many different servers)
Try it yourself
- clear all cookies from your browser through the browser security and privacy settings
- open the developer tools in the browser (F12)
- access a website e.g. irishtimes.com
- in the Network window of the developer tools panel click on the original request (for the root, /)
- look at the request header - it shouldn't contain a cookie
- look at the response header and find the set-cookie field that came from the server
- examine the set-cookie header field, find the attributes and interpret them
- now reload the page in the browser
- the request header should now contain the Cookie field (with the same cookie that was received from the server)
- have a look at the response header - it should not have any cookie-related fields (the cookie has been set for this user and does not need to be set again)
-
URL Re-writing
URL Re-writing
URL re-writing
- does not require any action on the part of the browser (like with cookies, which need to be sent as part of a request header)
- is more limited than cookies (the session lasts only while the user keeps coming back to a website through links from the website itself)
- the mechanism consists of the server adding an id parameter specific to the client into any link inside the page it is serving
Example
- A client requests a page called abc.html from a server, not having visited this particular server before.
- The page looks like this:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"/> <title>All Bins Collected</title> </head> <body> <h1>Choose your bin type</h1> <a href="green.html">Green Bins</a> <a href="gray.html">Gray Bins</a> <a href="brown.html">Brown Bins</a> </body> </html> - Instead of sending the page back as it is, the server assigns an id to the client, e.g. 123456, and inserts it as a argument into all the links in the page before sending it in the content part of the response:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"/> <title>All Bins Collected</title> </head> <body> <h1>Choose your bin type</h1> <a href="green.html?id=123456">Green Bins</a> <a href="gray.html?id=123456">Gray Bins</a> <a href="brown.html?id=123456">Brown Bins</a> </body> </html> - If the client clicks on any of the links, the request will now include the client's id, identifying the client to the server and so continuing the session.
-
Hidden Form Fields
Hidden Form Fields
Hidden fields in forms
- are a mechanism very similar to URL re-writing, differing in where the session-identifying information is placed
- can be used only when the client's requested page includes an html form
- the server's response includes the requested form, which, apart from the functional form fields, includes a pre-filled hidden field
- when the form is submitted by the client the server receives the value in the hidden field, which identifies the session
Example
<form> <!-- other form fields here --> <input type=“hidden” name=“session” value=“11232477”> </form>
Tallaght Campus
Department of Computing
Session Management